编码
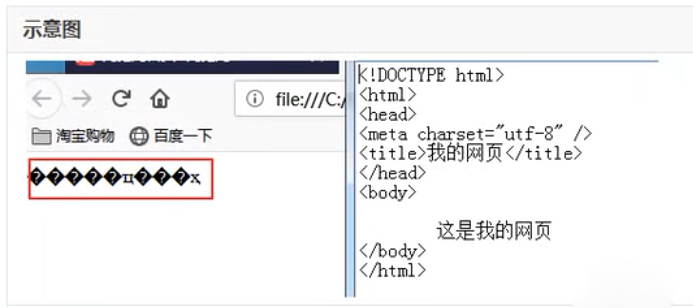
这种情况就是乱码,是因为我们输入的中文,往往计算机保存的时候,最终都要转成2进制的数据形式,也就是说有一个编码的过程,在保存文件的时候默认使用的是ANSI编码格式,浏览器显示文件中内容的时候,还需要将2进制的数据转换成文字形式显示出来,也就是说还有解码的过程,浏览器被指定为utf-8来解码,也就是说编码和解码不一致所造成的乱码。
字符集
ansi:不同的国家和地区制定了不同的标准,由此产生了GB2312、GBK、Big5、Shift_JIS等各自的编码标准。这些使用1至4个字节来代表一个字符的各种汉字延伸编码方式,称为ANSI编码。在简体中文windows操作系统中,ANSI编码代表GBK编码;在日文windows操作系统中,ANSI编码代表Shift_JIS编码。不同ANSI编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段ANSI编码的文本中。
unicode:Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
字符编码
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码,用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
GB2312是一个简体中文字符集,由6763个常用汉字和682个全角的非汉字字符组成。其中汉字根据使用的频率分为两级。一级汉字3755个,二级汉字3008个。
GBK即汉字内码扩展规范,K为扩展的汉语拼音中"扩"字的声母。英文全称Chinese Internal Code Specification。
GBK编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。